Adblock Plus and (a little) more
Investigating filter matching algorithms · 2006-08-22 20:02 by Wladimir Palant
Warning: dense computer science talk ahead. Proceed at your own risk!
This is the story behind improving the performance of Adblock’s most important component — filter matching. The problem is the following: we have a set F consisting of f filters, we have a string (an address) S of length n, and we need to know whether this string matches any of the filters. If it does, we need to block the element associated with this address. And we should decide really soon because there are a few hundred more of those addresses to be tested and the user is waiting impatiently.
What does Adblock do, what did Adblock Plus 0.5/0.6 do? They all used the trivial algoritm:
function getMatchingFilter1(S, F)
for each filter in F
if (filter matches S)
return filter
end if
end for
return null
end function
The complexity of regexp matching is roughly something like O(n) meaning that the overall complexity of the algorithm is O(n ⋅ f). Which is bad, since the performance depends on the number of filters. Consequently, users try to improve performance by compressing their list of filters at any cost. Amongst others that would mean using large and totally incomprehensible regular expressions as well as too general filters.
Can we do better? When we deal with regular expressions that are pretty much a black box for us — no, we really have to test all the filters, any of them might match here. And we don’t want to get into business of analyzing the semantics of regular expressions, that’s a science on its own. Fortunately, most filters are not (or rather: should not be) specified as regular expressions, they are only converted to ones. And from those simple filters we can extract a characteristic substring (“shortcut”) that we know must be present in any string matched by the filter.
This changes our problem quite significantly. Instead of a set of filters we have a set of shortcuts C of length m. And we look up these shortcuts in S — if we find one, we have to test the string against the corresponding filter. And we only need to test against filters whose shortcuts we find, meaning that this operation will happen rarely, and only the effectiveness of the shortcut search is relevant for the overall performance.
Note: we still might have a number of filters that have been specified as regular expressions or that don’t have enough text to extract a shortcut from. For those we are stuck with the trivial algorithm which doesn’t mean that we cannot process the other filters separately and more efficiently.
Some might recognize the problem as string search using a finite set of patterns. My first approach to solving it simply stored all shortcuts in a hash table H and looked up all substrings of S with length m in this hash table:
function initializeHashTable2(H, C)
for each c in C
H(c) := filter(c)
end for
end function
function getMatchingFilter2(S, H, m)
for each substring in (substrings of S with length m)
if (substring in H and H(substring) matches S)
return H(substring)
end if
end for
return null
end function
Hash tables aka associative arrays in Gecko’s JavaScript are well-implemented enough to assume O(1) complexity for store and lookup operations here. This gives us complexity O(f) for hash table initialization but that’s something that only needs to be done once. As to the actual matching — S has O(n) substrings, and substring extraction has constant execution time in JavaScript which gives us the overall complexity O(n). Note that it does not depend on f meaning that we can now have as many filters as we like — which is great! And that’s also the reason why Adblock Plus 0.7 uses this algorithm, with m = 8 (chosen rather empirically).
Now that we got the theoretical complexity right, we need to worry about the practical execution time. Substring extraction isn’t exactly well-known as the most effective operation, and consequently Adblock Plus has to switch to the trivial algorithm whenever we have less than 100 filters — the execution time is simply lower then. Maybe we should find a way to avoid working with substrings?
Rabin-Karp algorithm looks like the ideal solution. Its computational complexity is O(n), meaning that we aren’t loosing anything here. It is very similar to the algorithm above but replaces the expensive substring operations by straightforward integer operations (hash function calculation). Furthermore, we can choose our shortcuts here in such a way that we don’t have any hash collisions. And yet, when I implemented this algorithm it slowed everything down by factor two. What went wrong? It seems that the JavaScript method String.charCodeAt() requires almost the same time as String.substring(), a rather interesting implementation detail. Once we notice that Rabin-Karp algorithm calls String.charCodeAt() twice for every character in the string to compute the hash whereas the algorithm above calls String.substring() roughly once per character, the reason for the strange result becomes clear.
This means however that in JavaScript going down to the character level won’t give us any advantage over working with substrings, that’s very different from any compiled language. So instead of replacing calls to String.substring() we need to focus on reducing their number. We need an algorithm that skips several characters before testing again — like the Boyer-Moore algorithm. Now Boyer-Moore is a single-pattern search algorithm that also works on the character level. I thought about ways to adapt it and found that instead of building a jump table based on characters we can build a jump table J for pattern substrings of length m/2 (assuming m is an even number):
function initializeHashTable3(H, J, C, m)
for each c in C
H(c) := filter(c)
for i in (0 .. m/2)
substring := c.substring(i, m/2)
jump := m/2 - i
if substring not in J or J(substring) > jump
J(substring) := jump
end if
end for
end for
end function
function getMatchingFilter3(S, H, J, m)
endPtr := m
while endPtr <= n
substring := S.substring(endPtr - m/2, m/2)
if substring in J and J[substring] > 0
endPtr := endPtr + J[substring]
else if substring in J and J[substring] = 0
substring := S.substring(endPtr - m, m)
if (substring in H and H(substring) matches S)
return H(substring)
else
endPtr := endPtr + 1
end if
else
endPtr := endPtr + m/2 + 1
end if
end while
return null
end function
We move through the string in the same way Boyer-Moore algorithm does. First test a substring of length m/2: if our jump table tells us that there are patterns containing this substring we adjust our current position accordingly. If the jump table tells us that we don’t need to adjust — the substring is potentially the ending of a pattern and we need to test whether this is the case and whether the corresponding filter matches the string. If this test fails we can only move our current position by 1 (a fallback table might help but so far it doesn’t look like this situation would happen all to often). And finally, if the substring isn’t in the jump table we can jump by m/2 + 1 characters — we know that no pattern contains this particular substring.
The best-case complexity here will be O(n/m), worst-case O(n) (and actually factor two slower than the previous algorithm since it calls String.substring() at most twice for every position). The tests indicate that that actual execution time is pretty near to the best-case but gets slightly worse once the jump table fills up. Here are the test results for all three algorithms, with two different filter lists but the same set of addresses:
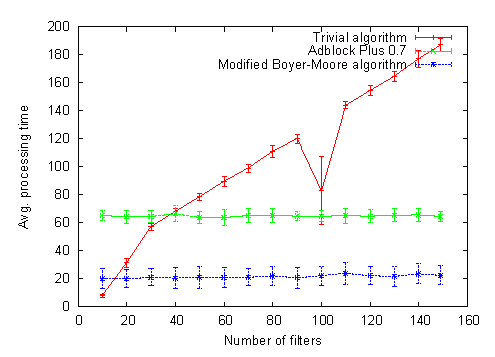
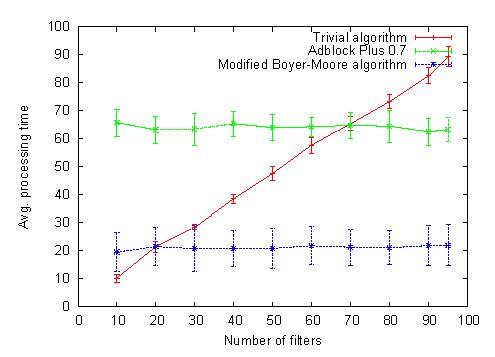
Note: I cheated a little here. What is called “Adblock Plus 0.7” in these graphs isn’t really the implementation used in Adblock Plus 0.7 — I changed an implementation detail which gave it a ~30% speedup. Yet the new algorithm is still considerably faster.
Well, it looks like I will use this algorithm in Adblock Plus 0.7.2 unless something better comes up. It gets equal with the trivial algorithm already at 15-20 filters, meaning that I can stop switching to the trivial algorithm when we have too few filters (the 10ms difference are not worth it). We get a 20-30% increase in initialization time which is O(f ⋅ m) now, this should be tolerable. We need additional memory for the jump table — it seems to contain on average 1.5 entries for every filter, that won’t consume a noteworthy amount of memory. And, to round up: here is how we perform with really many filters:
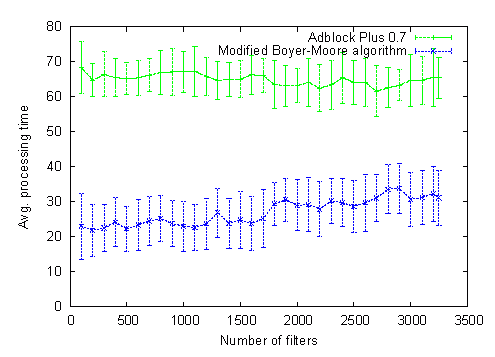

Comment [9]
Commenting is closed for this article.
ecjs · 2006-08-22 22:12 · #
“Rabin-Karp algorithm calls String.charCodeAt() twice for every character in the string to compute the hash”
There is no way to improve this algorithm, isn’t it ?
To sum up your article, you are a real programmer, which means you think about the complexity of an algorithm before you start the serious programming work. Well done !
Reply from Wladimir Palant:
No, I don’t think it can be improved. The main assumption of the algorithm is that integer operations (including those with the string characters) are more efficient than string operations. But JavaScript is a high-level language where this assumption is simply not true — bad luck. If I could write the extension in C++ everything would be different of course…
BigDuck · 2006-08-23 13:01 · #
Is Adblock Plus your dissertation or why do you invest more time and resources in Adblock (Plus) than anyone has done before!
More extension would need such a enthusiastic developer. Thanks for everything you have done and do and will for Adblock Plus. Keep at it!
Pumbaa80 · 2006-09-06 11:09 · #
Wow, great job!
“Once we notice that Rabin-Karp algorithm calls String.charCodeAt() twice for every character in the string to compute the hash”
Is that really necessary? I mean, why don’t you calculate String.charCodeAt() once for each char in S, store the results in an array T, and do the hashing with T?
Reply from Wladimir Palant:
It won’t help – we will only get a complicated algorithm that will perform just as good (or more likely somewhat worse) as the current simple algorithm. But I want one that will perform better.
MattH · 2006-10-25 00:59 · #
So – this all applies to substrings only? Regex strings will fall back to the trivial (aka slow) algorithm?
What criteria do you use for falling back? For example, some of the regex’s in the publicly available filter lists (e.g. EasyList) could be trivially converted to substrings (e.g. /Banners/, /partners/ , etc).
If Regex strings are poor, then is there anything being done to:
a) convert simple patterns (e.g. /Banners/) to strings during initialization?
b) reach out the main list creators (e.g. EasyList) to give them some guidance on optimizing their lists?
Reply from Wladimir Palant:
Yes, regexps always fall back to the trivial algorithm, simple patterns do not – if they have enough text in them. I recommend subscription authors to use the deregifier, Adblock Plus won’t do this internally for performance reasons. And I am in touch with the subscription authors to help them optimize their lists for Adblock Plus.
Btw, EasyList doesn’t have any regexps, you must be confusing something here.
Mecki78 · 2007-11-29 21:57 · #
I can imagine why charCodeAt is as slow as substring matching. When I was going to implement a script interperter, I’d try to speed it up by doing as much work in C/C++ as possible. That means I will create a bridge from the script language to my native implementation and wherever possible perform the operation as native operation (as it is hundred times faster than implemeting the operation in the script language itself).
So every call to charCodeAt would be translated over the bridge to a native C funktion that returns the charCode at this position. For the substring match, it would be translated to a C function, that does the substring match. If you’d profile the whole thing, you’d see that the time spend in my C function (whether it does a substring match or just looking up a single character) is so small compared to the bridge translation, that it is negligible. IOW the way over the bridge into and out of my native code is what actually takes the time here, not the thing my C function is doing.
I guess the JS call to the function will be about 95% for the substring match and about 99% for the charCodeAt function. In both cases, over >90% is spent for the call itself. This means reducing the number of calls itself only by 50% speeds up the whole process much, much more (by about 48%) than switching from the slower call to the faster call (which might speed it up by 2% at most).
Note, that these are just my two cents, I have no idea how the JS implementation of Mozilla works :)
Still, implementing the deregifier into the addon would be cool. It don’t needs to run every time a page is opened. It only needs to run once if the filter is added and again if it has been edited, then, a second, invisible, shadow filter is added (or maybe a couple of shadow filters), which is the real filter being used, the other one is just the one displayed to the user; that is, unless the regex is so complicated that it can’t be deregified, in which case the real regex is used.
Reply from Wladimir Palant:
Yes, I thought the same when I saw the results of Rabin-Karp – algorithmically it is better but the overhead for the many function calls is eating up all the advantage (at least as long as you operate on realistic sample sized). JavaScript is simply not C++ where charCodeAt would be an extremely cheap operation.
isaac levy · 2008-11-23 08:31 · #
So firefox extensions are always done in javascript? I suppose that’s fine for most extensions, but I wonder if adblock plus could be split into parts:
1) Extension that does the tight integration into firefox
2) Plugin/resident program on computer – compiled code which does the heavy lifting.
I haven’t read speed specs for adblock plus currently, all I’ve seen in mention of initialization slow downs, but it’s possible such a move could be worth it. Of course, it adds complexity to maintain the program, adds complexity to install adblock, and adds complexity to uninstall.
it’s a mess, but JS is slow for stuff like this, which of course you know since you’ve written a M.S. thesis here.
anyway, cheers. keep up the great work.
Isaac
Reply from Wladimir Palant:
I have been considering adding a binary component for a while – but I am still not sure whether it is worth it. JavaScript is platform-independent, a binary component would need compiling on at least three platforms. And then there is much higher effort writing code and higher probability of bugs of course.
Thibault · 2008-12-02 15:51 · #
Very interesting article. Thank you for your work on ABP and your patience to explain the internals.
I have a few questions:
1) I’m quite surprised that the performance of the 0.7 algorithm (getMatchingFilter2() I suppose) increases with f, whereas the Boyer-Moore one is slightly decreasing when f grows – which is less surprising given the amortized constant time hashtables provide. Do you have explanations to this phenomenom or is it statistically insignificant ?
2) Did you perform tests with the actual filtersets available ? Depending on the proportions of regexps in them, they might react totally differently
This is just out of my curiosity – I am pretty amazed what you could do with JavaScript and a bit of imagination. The best Firefox extension ever.
Cheers
Reply from Wladimir Palant:
1) I think this is statistically insignificant, that’s fluctuations in hash table implementation.
2) I did, using some huge list of filters and only using the first N filters of it. It didn’t have any regular expressions but you can easily imagine what effect those will have – they are still handled by the trivial pre-0.7 algorithm. So for example with 70 regular expressions you will get the usual Boyer-Moore results plus 65 milliseconds.
Nick · 2009-12-27 21:00 · #
Nice work.
If each of the filters is a separate Regular Expression, you can construct a DFA that matches the Regular Expressions of all filters simultaneously.
Determining if a URL matches any of the filters will take O(N) time where N is the length of the URL, independent of the number of filters. (Each DFA state stores the index of the first matching Filter, if any.)
This technique can be used lexical analysis of many compilers to match all keywords simultaneously.
Granted, the construction of the DFA will take time, but you only need to do this when the filter set changes. Also, this can be greatly reduced by constructing the transition table for the DFA in a lazy manner.
See Compilers Principles, Techniques and Tools, Aho, Sethi Ullman (The Dragon Book).
Specifically, Algorithm 3.5. Construction of a DFA from a regular expression r In Section 3.9 “Optimization of a DFA-Based Pattern Matchers”
You need to modify the algorithm to use separate augmentation symbols, one for each pattern.
Reply from Wladimir Palant:
True, that’s an option I forgot about. Note that JavaScript’s regular expressions aren’t actually regular expressions and cannot be expressed using a DFA. Also note that there are pathological cases where the number of DFA states (and thus memory use) is exponential in the number of regular expressions. Still, a nice idea, maybe I can use it somehow.
Daniel · 2010-03-29 18:16 · #
I came here to say something similar to what Nick just said :) At first thought, using the minimal automaton of all the filters OR‘d together would yield very fast lookups.
I don’t know exactly up to which scale calculating the minimal DFA is viable, but it’s worth looking into (there are efficient algorithms; it’s not some NP-hard combinatoric problem AFAIK).
About non-regular features (which are these btw?) of Javascript regexps: I assume these are rare in filters — just special-case them out of the whole automaton-based match?
Btw I’m not complaining, ABP is great as it is; just pondering the possibilities.
Reply from Wladimir Palant:
It so happens that I tried DFA (or an algorithm that is essentially a DFA) only a few days ago. Guess what – the performance was 6 times worse than what we have now even though that algorithm should have performed better. Really, with JavaScript the performance isn’t always what you would expect. But I’ll luckily accept patches that do the job better, matcher.js is the file you should modify in the source code ;)
As to non-regular features – these features (esp. look-ahead expressions) are almost the only reason one would use raw regular expressions with Adblock Plus these days.